Word Error Rate forteller om nøyaktigheten til talegjenkjenningssystemet
Word Error Rate (WER) er et ofte brukt mål for å evaluere nøyaktigheten til talegjenkjenningssystemer. WER måler hvor mange feil et talegjenkjenningssystem gjør ved konvertering av tale til tekst. WER beregnes ved å sammenligne den gjenkjente teksten med originalmanuskriptet og identifisere forskjeller som tilføyde, manglende eller feilgjenkjente ord.
WER beregnes som følger:
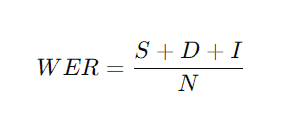
- S er feil erstattet ord (Substitutions),
- D er manglende ord (Deletions),
- I er ord som er satt inn (Insertions),
- N er antall ord i originalteksten.
I praksis kan WER brukes til å evaluere ytelsen til talegjenkjenningssystemet i ulike brukssituasjoner. Det er et nøkkelmål ved utvikling og forbedring av automatiske talegjenkjenningssystemer, som også brukes som et hjelpemiddel i for eksempel Spokens teksting og transkripsjonstjenester.
Jo lavere WER, jo mer nøyaktig er talegjenkjenningssystemet. Å redusere WER er derfor et hovedmål for selskaper og forskere som fokuserer på å fremme talegjenkjenningsteknologi.
Whiper- og WER-verdier for ulike språk
Hos Spoken bruker vi OpenAIs Whisper-talegjenkjenningsmodell for talegjenkjenning, hvor WER-verdiene varierer avhengig av språk. I engelsk talegjenkjenning er WER vanligvis den laveste og dermed den beste, på grunn av den store mengden data som er tilgjengelig og det faktum at modellen er optimalisert for det engelske språket.
For engelsk kan WER være så lav som 5-6%. I norsk, svensk og dansk talegjenkjenning er WER-verdiene litt høyere enn dette, rundt 8–10 %. På finsk kan WER være enda høyere enn dette, rundt 10–12 %, på grunn av den unike strukturen og morfologien til det finske språket, som utgjør spesielle utfordringer for talegjenkjenningssystemer.
Denne sammenligningen viser at mens Whisper er svært effektiv for mange språk, har språkstruktur og datatilgjengelighet en betydelig innvirkning på WER.